
The Coherence Record, Edition 5
The instrument learned to question itself. Then it gained depth.

Justin R. Greenbaum | Founder, Greenbaum Labs
March 2026

What’s Happened
Edition 4 ended with the strongest claim in this project’s history: the instrument is reproducible. Zero standard deviation. Same entity, same score, every time. Finding-derived scoring replaced the LLM’s opinion with deterministic computation. The pipeline was grounded.
That was published on March 5. By March 13, eight days later, the project changed shape again.
134 runs in the ledger now. This is what the last eight days produced.
The Prompts Weren’t Good Enough
Edition 4 proved the scoring architecture was sound. It did not prove the prompts were.
Con-Hotel’s original run, run 079, scored with 33% skeptic throughput. Two of six findings survived debate. The other four were rejected. The rejected findings followed a consistent pattern: the agent had decided what score felt right, then went looking for evidence to justify it. The findings read like conclusions wearing an evidence costume.
This is the same failure pattern twenty-seven runs had eliminated from the scoring architecture, the model generating an opinion instead of computing from evidence. Fixed in the formula. Not fixed in the prompt.
Two changes:
First, Evidence Discipline blocks were added to the truth and authority scorer prompts. These are structural constraints, not suggestions. The prompt now explicitly names the failure pattern, “starting from a conclusion and working backward,” and forbids it. It requires each finding to be built from cited evidence: specific claims, specific observations, specific scope. The finding follows the evidence. Not the other way around.
Second, the authority few-shot examples were rewritten. The old examples were abstract. They led the model to produce vague, general findings that sounded analytical but said nothing specific enough to survive the Skeptic. The new examples follow a progression: BAD (vague, unsupported), STILL BAD (specific but backward, conclusion first), GOOD (evidence first, finding emerges from the data). Each example is led by a specific customer quote, not a category label.
Con-Hotel rescore with the hardened prompts: 83% skeptic throughput. Five of six findings sustained. Triple-blind validation confirmed deterministic, 0.000 standard deviation.
The prompts are now committed to the pipeline repo. The same codebase that runs the fleet.

Autoresearch
The prompt changes that fixed Con-Hotel were designed by hand. The Skeptic’s rejections were analyzed, the failure pattern was identified, and the prompts were rewritten to prevent it. That worked. But it does not scale.
So the lab built the machine that does it.
Andrej Karpathy recently open-sourced a similar concept, an agent that iterates on ML training code autonomously, running experiments while the operator sleeps. Different domain, same principle: structured experimentation at a pace no human can match. The Greenbaum Labs version optimizes diagnostic prompts against an adversarial debate mechanism.
Autoresearch is a harness that runs prompt experiments automatically. It takes a frozen extraction, same claims, same observations, and tests prompt variations against it, measuring skeptic throughput, scoring correctness, and reproducibility. Each experiment produces a structured log: what changed, what the scores were, whether the findings survived debate.
Between March 10 and 12, the Sparks ran 60 experiments across two tracks.
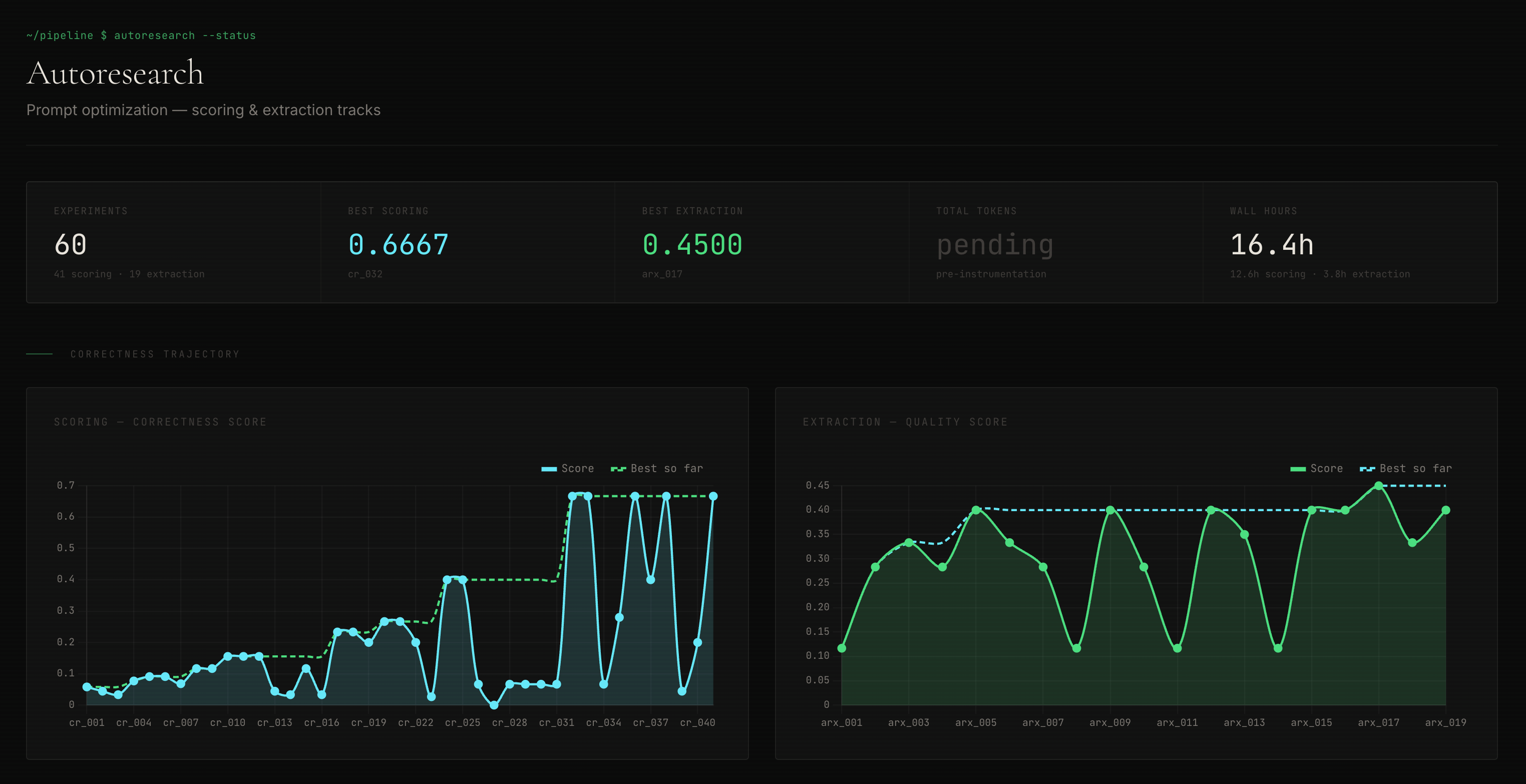
The scoring track ran 41 experiments. The baseline, Edition 4’s prompts before the Evidence Discipline changes, scored 0.058 on the optimization metric. The best variant scored 0.667. An 11.5x improvement. The key discovery wasn’t a single brilliant prompt. It was that asymmetric extraction limits, pulling 3 items from center sources and 5 from edge sources, outperformed symmetric limits. The edge is where the signal lives. Give the model more of it. The scoring track converged. Later experiments showed diminishing returns. The prompt space for scoring is largely explored. That means the current prompts are near the ceiling for what prompt engineering alone can achieve.
The extraction track ran 19 experiments. Baseline 0.117, best 0.450. A 3.8x improvement, with more room to run. Extraction is upstream of everything, the quality of claims and observations determines what the scorer has to work with. This track matters more than the scoring track in the long run. No convergence yet. The runway is open.
The harness is 7,165 lines of code. It runs unsupervised. It produces structured, reproducible experiment logs. And it confirmed something previously suspected but never measured: the pipeline’s reproducibility is near-perfect even as correctness varies. Fleet average reproducibility across cross-entity validation: 0.998. The instrument produces the same answer every time, even when the answer is wrong. That is the foundation. You fix correctness once and it stays fixed.
Prompt optimization is not craft anymore. It is experimental science. Hypothesis, test, measure, iterate. The machine questions the machine.
Three Machines, One Night
On the night of March 12, three jobs were launched across three machines.
Spark 2 rescored runs 070 through 084, the March 6 collection, all fifteen fleet entities, with the hardened prompts. M2 Studio rescored runs 049 through 064, the February 20 collection, the same fifteen entities, with identical prompts. Spark 1 ran Con-Hotel end-to-end, run 085, full extraction and scoring with the hardened prompts.
Everything completed overnight. Thirty rescores and one full pipeline run, across three machines, without intervention.
Six weeks ago the operational workflow required manual SSH checks on each machine, NAS mount debugging, and hand-verification of every flag in every launch command. Three failed Con-Hotel launches in a single session, wrong environment, wrong mode, missing flags, forced the construction of proper pre-flight checks.
The overnight run confirmed that the operational infrastructure caught up to the analytical infrastructure. The pipeline was reproducible weeks ago. The operations around it were not. Now they are.
The Numbers
Fleet rescore v4 results, March 6 collection (fifteen entities, hardened prompts):
Fleet average overall: 0.452. Range: 0.370 (Tech-Oscar) to 0.496 (Tech-Mike, Fin-Foxtrot). Truth average: 0.491. Authority average: 0.398.
For comparison, the original scores on this collection averaged 0.455 overall. The fleet moved down by 0.003. Effectively unchanged. But what moved underneath matters.
The biggest individual shifts:
Fin-Delta: Truth rose from 0.455 to 0.554 (+0.099). The original scoring had suppressed a real signal, center-edge alignment on financial performance that the Evidence Discipline prompts now surface properly.
Tech-Oscar: Overall dropped from 0.450 to 0.370 (−0.080). The original scoring had been generous. The hardened prompts derived a lower score from the specific findings that survived debate. The old scorer gave Tech-Oscar credit the evidence didn’t support.
The pattern is the same one from Edition 4’s rescore: the system corrects in both directions. Upward where signal was suppressed. Downward where opinion had inflated. Calibration, not drift.
Skeptic throughput across the v4 fleet: 48% (44 of 90 findings sustained). Tighter than the original runs’ 57%. The hardened prompts produce fewer findings overall, but the ones that survive are better grounded. Quality over quantity. That is the design intent.
February 20 collection rescored with identical prompts: fleet average overall 0.443. Range: 0.386 (Fin-Echo) to 0.496 (Aero-Charlie). Comparable distribution, different collection date, same methodology. The scores are in the same band because the instrument is calibrated, not because the entities haven’t changed.
Run 085, Con-Hotel full end-to-end with hardened prompts: overall 0.460 (finding-derived). Truth 0.500, Authority 0.410. The extraction pulled 201 claims and 2,559 observations from the collection. Skeptic throughput was low, 20%, one finding sustained out of five. The Skeptic was harsh on this run, and the surviving finding was strong. The system working correctly. A low throughput rate with strong surviving findings is a more honest result than a high throughput rate with weak ones.
Against Con-Hotel’s original run 079 (overall 0.427), run 085 gained 0.033. A modest improvement. The real difference is in the evidence quality. The finding that survived debate in 085 is grounded in specific claims and observations. The findings that survived in 079 were vaguer. The score is similar. The confidence behind it is not.
Continuity

Every edition of this record has contained the same line: “Continuity remains unscorable. One collection period.”
That line is retired.
The February 20 and March 6 collections, both scored under finding-derived v1 with hardened prompts, provide the two temporal points needed to compute Continuity. For every entity in the fleet, there are now two readings on the same instrument, separated by two weeks.
Two weeks is not much. But it is infinitely more than zero. And the structure is in place for the next collection, and the one after that.
What Continuity measures is trajectory. Truth and Authority are snapshots, where is this organization right now? Continuity asks: is it getting better, getting worse, or holding steady? Is the compression increasing? Is the center-edge gap widening or closing? Are the same failure modes persisting, or are new ones emerging?
The diagnostic becomes most valuable here. Not “here is your coherence” but “here is where your coherence is heading.” A snapshot tells you what to investigate. A trajectory tells you what is urgent.
The entity-level deltas between February 20 and March 6 are the next computation. The data exists. The methodology is identical. The analysis is coming.
Findings
Edition 4 appeared to be a conclusion: reproducibility proved, architecture locked, fleet scored. It was not a conclusion. It was the foundation for a harder set of questions.
The prompt deficiency was discovered by using the instrument, not by theorizing about it. The Skeptic’s 33% throughput on Con-Hotel meant four findings were rejected, and the rejection rationale pointed to the prompt, not the scorer. The instrument diagnosed its own inputs. That is a real feedback loop.
Automating prompt optimization appeared to be a shortcut. It is not. It is the only way to explore a space this large with any rigor. The autoresearch harness ran 60 structured experiments in three days, each one isolating a single variable. Combined with the 13 hand-tuned experiments that preceded it, 73 total experiments shaped the current prompts. No manual process achieves that. Not in three days, not in thirty. The machine is better at questioning itself than the operator is at questioning it.
A structural shift occurred in the last eight days. Editions 1 through 4 were construction: designing the architecture, fixing the scorers, debugging the pipeline. The relationship was builder to tool. With autoresearch, the instrument improved itself. The operator set the constraints, defined the metrics, launched the harness, and read the results. The machine ran the experiments independently. Builder to observer. That is the shift underneath the numbers. The discipline is in the constraints, not the keystrokes.
The authority data constraint, carried as a cap through Editions 3 and 4, was lifted without ceremony. Employee reviews appeared in the March 6 collection for all fifteen entities. The internal voice that was entirely absent from the edge data now exists. The authority scores did not move much. That raises a harder question than the cap did: the constraint was clear and honest. Now the data is present and the scores are similar, and the next step is determining whether the instrument is surfacing what the employee reviews contain or whether the extraction and scoring prompts need to be tuned to this new source type.
Continuity changes what the project is. The instrument has been taking snapshots. Snapshots are useful. They show where compression lives, where the center-edge gap is widest, where authority is concentrated or diffused. But snapshots are inherently limited. One reading on a patient. No indication of trajectory. Continuity adds the temporal dimension. The vital sign over time. Lighting it does not just add a third vertex to the Triangle. It transforms the diagnostic from a static assessment to a dynamic one. That transformation is larger than any scoring architecture change or prompt improvement.
The overnight run is the operational milestone. Not because the computation was impressive, it is commodity inference on consumer hardware. Because the infrastructure held without the operator. The pipeline ran. The pre-flight checks caught errors before launch. The scoring was deterministic. The results landed on the NAS. Morning review confirmed completion. That is operations, not engineering. The project crossed that line sometime in the last eight days.
What’s Capped
The structural constraints from Edition 4 remain, with two significant changes.
The authority cap has been partially lifted. The March 6 collection includes employee reviews for all fifteen entities, approximately 100 Indeed reviews per entity with ratings, positions, and locations. This is the first time the pipeline has had internal voice data in the edge sources. The February 20 collection still has no employee reviews; that cap remains.
The v4 rescore of the March 6 collection had access to this data, and run 085 (Con-Hotel, full end-to-end) confirmed that claims were extracted from employee reviews. Authority scores on the March 6 collection still cluster between 0.375 and 0.500. Whether that clustering reflects a genuine measurement or whether the extraction and scoring prompts are not yet surfacing the employee review signal effectively is an open question. The data constraint is lifted. Whether the instrument is fully using that data is the next thing to verify.
Overall confidence remains capped at 0.60. Same reasoning. The data supports measurement within a range, and the system reports that range rather than inventing precision it doesn’t have.
Continuity is no longer dark. Two collection points exist. The computation is next. The cap here is temporal; two weeks of separation limits what the trajectory can reveal. More collection points, more widely spaced, will deepen the signal. But the vertex is lit. The infrastructure is in place.
What’s Next
The immediate work is the Continuity analysis. Fifteen entities, two collection dates, identical scoring. The deltas will show which entities shifted and in which direction. Some of those shifts will be real: a company changed its messaging, launched a product, faced a crisis. Some will be noise: collection variance, source availability differences. Distinguishing signal from noise in the Continuity vertex is the next methodological challenge.
The fleet needs to grow. Fifteen entities across five sectors gives trios in most industries. Enough to detect variation. Not enough to establish baselines. The vital-signs framing, coherence as organizational health metric, requires enough data points per sector to define what normal looks like. That work continues.
The autoresearch extraction track has room to run. Nineteen experiments, 3.8x improvement, no convergence yet. Extraction quality is upstream of everything. Better claims and observations mean better findings, which means better scores. The scoring prompts are near their ceiling. The extraction prompts are not.
And something else is taking shape. The taxonomy, seventeen failure modes, twenty-one field notes, the Coherence Triangle, was built for the pipeline. It was designed to be computed by machines against public data. But the patterns it describes are recognizable to anyone who has worked inside an organization. Immediately recognizable. An early external review produced this reaction: “You’re making the invisible, visible.”
The question forming is whether someone needs a pipeline to see these patterns, or just the right questions. Whether the instrument’s real contribution is not the scores it produces but the vocabulary it gives people for naming what they already observe. The next edition will follow that question.
The images in this edition are from my own library, shot on Leica over the last twenty years. Everything in this project is built or sourced firsthand. The visuals are no exception.