
The Coherence Record, Edition 4
Twenty-seven runs on one entity. What the instrument revealed about itself.

Greenbaum Labs
March 2026
What’s Happened
Edition 3 ended with a line I believed when I wrote it: “the instruments are getting sharper.”
They were not. They were producing numbers that looked like measurements but behaved like opinions. This edition is about discovering that, fixing it, and what became possible once the fix held.
Between February 26 and March 3, the pipeline ran twenty-seven hardening diagnostics on a single entity, rescored all fifteen fleet entities under a new scoring architecture, shipped two public websites, and defined consulting engagements. Six days. The most consequential week in the project’s history.
It started because I turned the instrument on itself.
The Variance Problem
Edition 3 flagged a specific concern: five entities landed at exactly 0.33 on Truth. I described this as a floor, the scorer compressing within the low range, unable to differentiate between moderately misaligned and severely misaligned. I proposed a wider aperture. That was the wrong diagnosis.
The problem was not the range of the scorer. The problem was that the scores were not measurements.
I discovered this by rescoring the same entity’s extraction eight times using the same model. Same claims. Same observations. Same scorer. Eight runs. Truth scores: 0.57, 0.43, 0.43, 0.62, 0.33, 0.62, 0.33, 0.33. Standard deviation: 0.114. Range: 0.33 to 0.62.
Authority, scored by the same process: standard deviation 0.021.
The truth scorer was not measuring coherence. It was sampling from a distribution of plausible-sounding numbers and returning whichever one the model generated on that particular inference pass. The five entities clustered at 0.33 in Edition 3 didn’t share a structural condition. They shared a scoring artifact. The model’s most common low-range output happened to be 0.33, the way a person asked to estimate something uncertain might repeatedly say “about a third.”
Authority was stable because authority findings are structurally constrained. Compression, diffusion, and misalignment are observable in the data. Truth is harder to pin down. The distance between what an organization says and what observers experience admits more interpretive latitude. The model used that latitude differently each time.
A diagnostic instrument with 0.114 standard deviation on its primary vertex is not an instrument. It is a random number generator with a plausible output range.
Twenty-Seven Runs
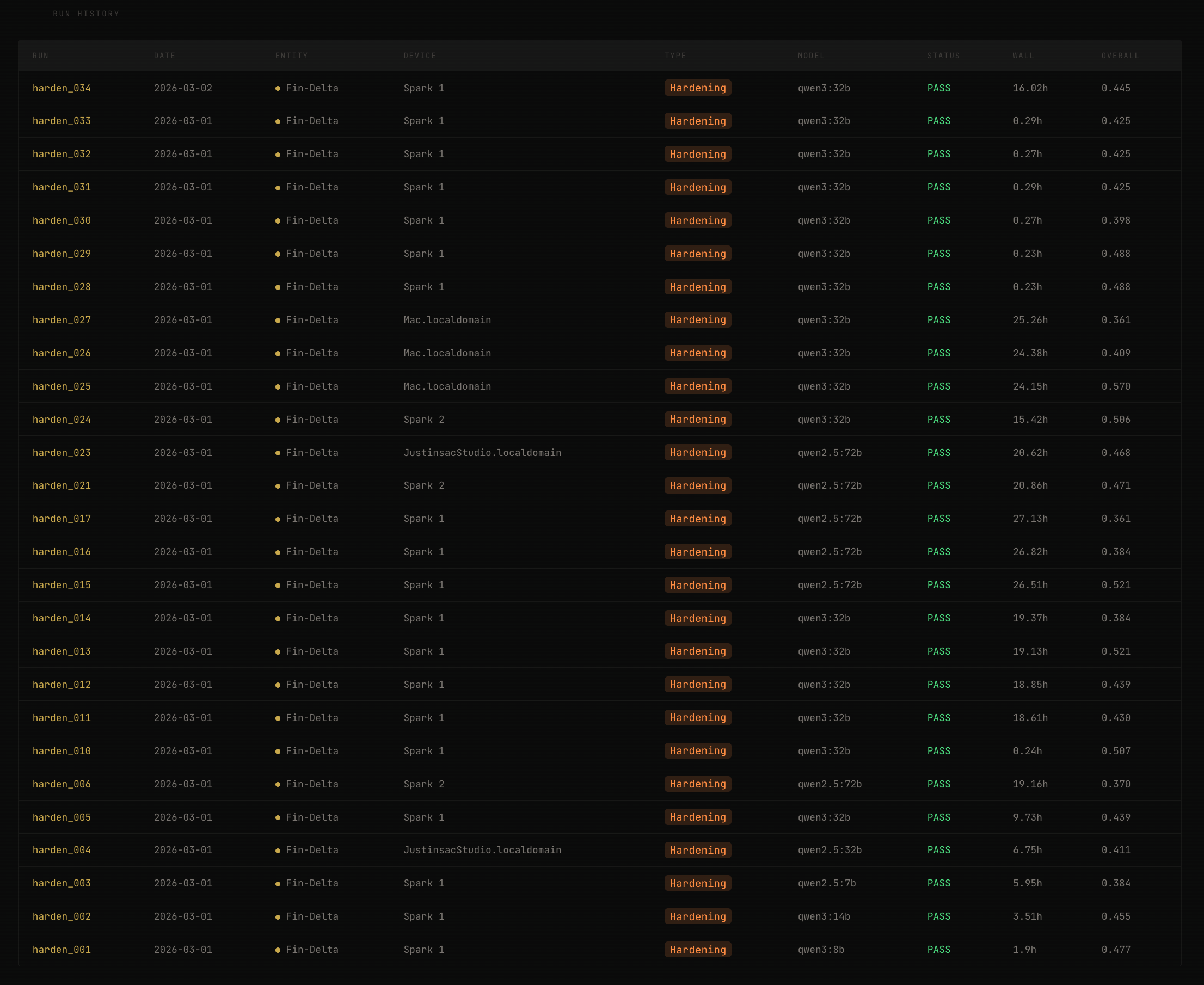
The hardening campaign was designed to isolate the source of variance systematically. Twenty-seven runs, all on a single entity, Fin-Delta, using the same collection date, the same pipeline version, varying one parameter at a time.
Phase 1: Model comparison. Six runs, six different extraction models ranging from 8 billion to 72 billion parameters, all scored by the same 32-billion-parameter model. The question: does extraction quality predict score quality?
It does not. The 8-billion-parameter model produced an overall score of 0.478. The 72-billion-parameter model produced 0.371. The smallest model outscored the largest. The scoring noise was louder than the model signal. This eliminated model capability as the explanation for variance and pointed directly at the scoring mechanism itself.
Phase 2: Reproducibility. Eight rescores of a single extraction, testing whether the same claims and observations produce the same scores when rescored by the same model. They did not. Truth ranged from 0.33 to 0.62. Authority held at 0.40 to 0.45.
The diagnosis was now specific: the Truth and Authority agents were returning a floating-point number, a single scalar that the model generated alongside its textual analysis. That number was an LLM opinion. It reflected the model’s general sense of where the score should land, not a computation grounded in specific evidence. Run the same prompt twice, get a different number. The textual findings were substantive. The numerical scores were not.
Phase 3: The architectural change. The solution was to stop asking the model for a number.
The agents already produced structured findings as part of their analysis. Each finding identifies a specific dimension (alignment, omission, or contradiction for Truth; compression, diffusion, or misalignment for Authority), cites specific claims and observations, and characterizes the strength of the evidence. These findings then pass through the Skeptic debate, where weak or unsupported findings are rejected.
The change: instead of using the model’s self-reported score, compute the score deterministically from the findings that survive the Skeptic. Each dimension has a calibrated base weight. Each strength level maps to a multiplier. The formula is fixed. The model produces findings. The math produces scores.
The calibrated bases, frozen after testing against the fleet’s existing data:
Truth: alignment shifts the score upward by 0.45, omission shifts it downward by 0.30, contradiction shifts it downward by 0.50. Authority: compression shifts downward by 0.25, diffusion by 0.18, misalignment by 0.22. A sparse-finding dampener prevents a single finding from saturating the score. If only one finding survives debate, its influence is scaled by one-third.
The agent’s original floating-point score is preserved in the metadata as an audit field. It no longer determines the production score.
Three validation runs under the new architecture showed immediate improvement. Authority standard deviation: 0.011. Truth still varied, not because the formula was unstable, but because the model was generating different findings each time. Same data, different emphasis, different findings, different derived scores.
Phase 4: Determinism. The remaining variance came from upstream. The stratified sampler that selects which claims and observations to present to each agent used unseeded random shuffling. Different samples meant different context, which meant different findings, which meant different scores.
Four changes eliminated this:
Seed the sampler. Each scope group gets a deterministic seed derived from a hash of its group key. The same entity always produces the same sample.
Sort claims and observations by identifier before sampling. Deterministic input order.
Constrain agents to exactly three findings per vertex, one per dimension. No more, no fewer. The model must produce one alignment finding, one omission finding, and one contradiction finding for Truth, each grounded in cited evidence.
Normalize finding phrasing with structural templates to eliminate stylistic drift between runs.
Three final validation runs. Truth: 0.4551, 0.4551, 0.4551. Authority: 0.3889, 0.3889, 0.3889. Overall: 0.4253, 0.4253, 0.4253.
Standard deviation: 0.000. The token counts were identical.
The pipeline is fully deterministic. Run the same entity twice, get the same score. Not approximately. Exactly.
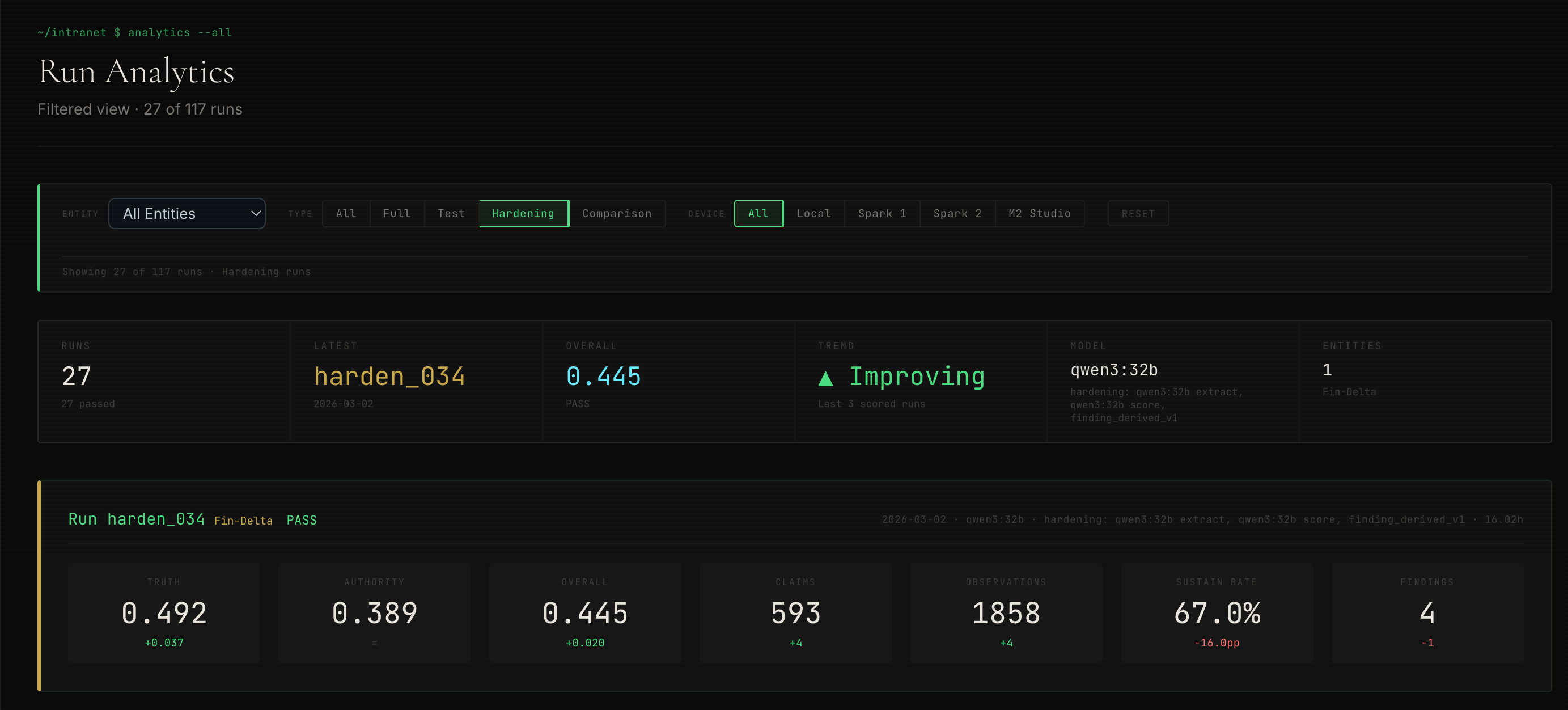
What Changed in the Scores
With the new scoring architecture locked, all fifteen fleet entities were rescored under finding-derived scoring. The same claims and observations from the original fleet run, scored by the new deterministic system.
The 0.33 truth floor is gone. Six entities that had clustered at exactly 0.33 now spread across 0.36 to 0.53. The scores differentiate. Aero-Alpha, which had been indistinguishable from Fin-Delta, Tech-Mike, Auto-Juliet, Fin-Foxtrot, and Aero-Charlie at the old floor, now scores 0.49 on Truth, a meaningfully different reading from Auto-Juliet’s 0.36 or Fin-Foxtrot’s 0.37.
Truth standard deviation across the fleet dropped from 0.096 to 0.067. Not because the scores compressed, but because the artificial clustering disappeared. The old scores had two modes: entities stuck at 0.33 and entities scattered above. The new scores form a continuous distribution. The instrument resolves the range where most readings land, which is exactly what Edition 3 said was needed.
Authority tightened further, from a standard deviation of 0.073 to 0.041. The old authority scores included an entity at 0.62 that was never supported by the evidence, an LLM opinion that happened to be generous. Under finding-derived scoring, authority clusters between 0.375 and 0.500, which reflects the structural reality that every entity in this fleet has the same constraint: no employee reviews in edge data. The scorer now acknowledges that constraint in its output rather than generating scores that imply resolution it doesn’t have.
Fleet average overall coherence moved from 0.458 to 0.445. A small downward shift. The new system is not more optimistic. It is more honest.
The rank order partially held, and in the places where it didn’t, the corrections were revealing. Tech-Mike moved from 0.33, indistinguishable at the floor, to 0.53, the highest Truth score in the fleet. A shift of +0.20, the largest in the rescore. The old architecture had suppressed a real signal. Tech-Mike’s center-edge narrative alignment was materially better than the rest of the fleet, and the scorer could not see it because it was generating a default low number instead of computing from evidence.
Auto-Lima moved the other direction: 0.50 to 0.40. The old scorer had been generous. The new one derived a lower score from the specific findings that survived debate. The system corrected in both directions: upward where signal was suppressed, downward where opinion had inflated. That is what an honest recalibration looks like.
Auto-Juliet and Fin-Foxtrot, which were invisible at the 0.33 floor, emerged as the fleet’s lowest Truth scores, a finding that was always there in the data but could not surface through the old scoring mechanism.
In Edition 3, I wrote that Aero-Alpha’s score was the fleet’s lowest, but cautioned that the data quality grade was the weakest and only one finding survived the Skeptic. Under finding-derived scoring, Aero-Alpha’s Truth rose from 0.33 to 0.49. The old score was the model’s default low output. The new score reflects the specific findings that survived debate. Aero-Alpha is still the weakest in the fleet on several dimensions. But the measurement now explains why, in terms that trace to evidence, rather than landing on a number the model reached for when it was uncertain.
What the Hardening Exposed
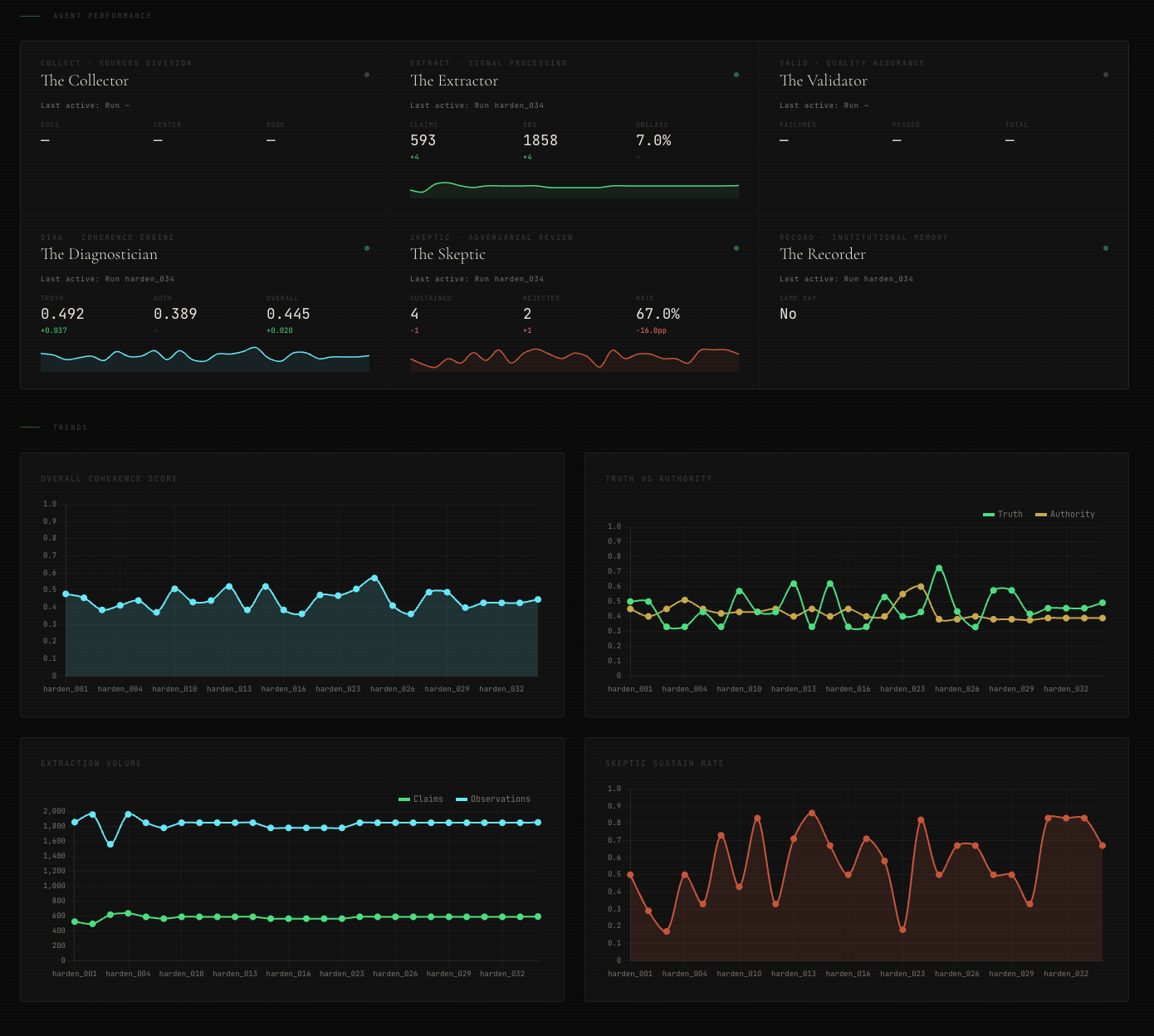
The twenty-seven runs answered the explicit questions they were designed to answer. They also revealed something I had not been looking for.
The scoring agents produce findings that are substantively valuable. They identify real patterns in the data. They cite specific claims and observations. The Skeptic debate correctly filters weak findings and sustains strong ones. This mechanism, the part that does the diagnostic thinking, was never broken.
What was broken was the translation layer. The agents did good analytical work and then generated a number that did not reflect it. The number was a separate act of inference, disconnected from the structured reasoning that preceded it. It was as if a physician conducted a thorough examination, identified specific clinical findings, and then reported a health score based on general impression rather than computing it from the findings.
Finding-derived scoring does not make the agents smarter. It makes their intelligence load-bearing. The structured findings that were always the most reliable part of the system now determine the output. The unreliable part, the scalar opinion, has been moved to an audit field where it can be studied without affecting the measurement.
This is a design principle, not just a bug fix. The principle: constrain the model to structured judgment, compute the measurement from the structure. Let the model do what it is good at: reading context, identifying patterns, evaluating evidence. Do not let it do what it is bad at: generating stable numerical outputs.
The Skeptic debate, for the third consecutive edition, proved itself the most reliable component. Across twenty-seven hardening runs and fourteen fleet rescores, findings were sustained when evidence was strong and rejected when evidence was weak. The adversarial mechanism’s judgment scales. Its reliability is the foundation that makes deterministic scoring possible. You can only derive scores from findings if the debate mechanism produces findings you can trust.
What’s Capped
The structural constraints from Edition 3 remain. But they sit on a different foundation.
Authority is still capped. No employee reviews in edge data. This affects all fifteen entities. The authority scores now cluster more tightly because the scorer is acknowledging the constraint rather than inventing resolution. That tighter clustering is honesty, not limitation.
Continuity remains unscorable. One collection period. One-third of the Triangle is dark. This has not changed.
Overall confidence remains capped at 0.60. The structural constraints are unchanged. What changed is that the scores within those constraints are now deterministic and evidence-grounded.
The difference matters. A capped score on a stable foundation can be incrementally uncapped as data improves. A capped score on an unstable foundation cannot be trusted even within its stated range. The fleet’s constraints have not changed. The trustworthiness of the measurement within those constraints has.
The Practice
With the scoring grounded, the infrastructure became a practice.
Engagement definitions, pricing, a diagnostic gift strategy with researched targets, and a brand and web presence across four sites, all built in forty-eight hours on March 2 and 3.
None of this would have been defensible with a 0.114 standard deviation on the primary vertex. You do not offer diagnostic services built on an instrument that generates different readings for the same patient. You do not describe a measurement system that cannot reproduce its own results.
The hardening campaign was not a prerequisite for the practice. It was the moment the practice became possible. The distance between “interesting prototype” and “field-grade instrument” is measured in reproducibility. Twenty-seven runs closed that distance.
What I Learned
The model’s opinion is not the measurement. This is the architectural lesson. LLMs produce text that reads like analysis and numbers that look like scores. The text is grounded in the prompt and the data. The numbers are generated by a different cognitive process: pattern completion in a latent space that has no concept of numerical precision. The solution is not to make the model better at generating numbers. It is to stop using generated numbers as measurements. Let the model analyze. Let the math measure. That boundary must be structural, not aspirational.
Reproducibility is not a feature. It is the minimum standard. Edition 3 reported scores without reproducibility testing. Those scores were published in good faith and are documented in the record. They were not wrong. The findings they were based on were real. But the numbers attached to those findings were unstable, and I did not know that because I had not tested it. The hardening campaign should have preceded the fleet run, not followed it. I built the fleet before I tested the instrument. That sequence was backwards.
Authority was always the stable vertex. Across twenty-seven runs with varying models, varying scorers, and varying sampling, authority standard deviation never exceeded 0.021. Truth varied by 5x that amount. This asymmetry was invisible until the reproducibility tests made it visible. Authority is stable because the patterns it measures: compression, diffusion, misalignment, are structurally legible in the data. Truth is harder because it requires comparing what organizations say against what is observed, and the interpretive latitude in that comparison is where the model exercises discretion. Constraining that discretion to structured findings was the right fix. But the fact that one vertex was stable and the other was not tells you something about the nature of the measurement, not just the quality of the scorer.
The Skeptic is the anchor. For the fourth edition running, the adversarial debate mechanism has been the most reliable component. It has now processed over a hundred runs across fifteen entities and two scoring architectures. Its behavior is consistent: challenge harder when evidence is thin, sustain findings when evidence is strong. The finding-derived scoring architecture is built on this reliability. If the Skeptic could not be trusted to correctly sustain and reject findings, computing scores from those findings would amplify errors rather than eliminate them. The fact that the Skeptic is reliable makes the entire downstream architecture viable.
You cannot sell what you cannot reproduce. This is the business lesson, and it is not about integrity in the abstract. A diagnostic practice requires that two runs on the same entity produce the same result. Not because clients demand reproducibility testing. Most will never ask. Because the practitioner must trust the instrument. Every recommendation, every finding, every conversation with a client flows from the diagnostic output. If that output is unstable, every downstream decision is built on sand. The hardening campaign was not a quality investment. It was the foundation of professional confidence. Without it, the practice would have been a performance.
What’s Next
The immediate work is building the second collection period for a subset of entities. Continuity, the third vertex of the Triangle, has been dark for every run in the project’s history. Lighting it requires temporal depth: at least two collection points, separated by enough time to observe narrative shifts, strategy changes, or structural drift. This is the next capability unlock, and it will change the shape of the diagnostic fundamentally. Truth and Authority are snapshots. Continuity is a trajectory. The first trajectory measurement will reveal whether the diagnostic framework can distinguish noise from trend, and whether the FM-01 vital-signs framing holds when you can measure not just whether compression is present but whether it is increasing.
The fleet needs more entities per sector. Fifteen entities across five sectors gives pairs and trios in most industries. That is enough to observe variation. It is not enough to establish baselines. The vital-signs framing, FM-01 as cholesterol, needing a resting rate to interpret, requires enough data points per sector to define what normal looks like. Twenty entities per sector is the threshold where baselines become defensible. The pipeline can run that volume. The collection infrastructure needs to scale to support it.
The fleet’s five-sector, three-entity-per-sector architecture was designed for falsification. It also produced something I had not planned for: the first competitive coherence benchmark. Within-sector comparison on identical instruments reveals which failure modes are structural conditions of an industry and which are specific to a single organization’s current state. That distinction, sector-wide versus company-specific, is where the diagnostic becomes most useful. Not just “here is your coherence,” but “here is how your coherence compares to direct competitors, measured the same way, on the same instruments.” The next edition will explore what that comparison reveals.
AR-001 Still Holds
Automation may observe, summarize, and suggest, but may not decide.
Finding-derived scoring did not change this principle. It reinforced it. The agents produce findings. The Skeptic evaluates them. The formula computes scores. Every step is observable, auditable, and deterministic.
But the diagnostic output is still a suggestion. It tells you where to look. It does not tell you what to do. A coherence score of 0.45 is not a verdict. It is an invitation to investigate what the findings describe. The human reviews the case summary, reads the evidence, and decides what it means in context.
One hundred seventeen runs. Fifteen entities. Five sectors. The pipeline does not decide. That is still by design.
What This Is Becoming
Edition 1 asked whether the infrastructure could exist. Edition 2 asked whether it could measure. Edition 3 asked whether it holds at scale.
This edition asked whether the measurement could be trusted.
The answer required rebuilding the scoring architecture, proving determinism, and rescoring every entity under the new standard. The instrument that produced Edition 3’s fleet scores was a prototype. It generated plausible numbers. The instrument that rescored that fleet is a calibrated tool. It computes grounded numbers. The difference is reproducibility, and reproducibility is not a technical property. It is the boundary between a demonstration and a practice.
The hardening campaign changed more than the scoring. It changed what the project is. A diagnostic prototype is interesting. A reproducible diagnostic instrument with a published methodology and a public build record is a practice. The scores are the same kind of object they were before: measurements of coherence across truth, authority, and continuity. But the confidence behind them is structurally different. Not confidence in the sense of a statistical interval. Confidence in the sense that a practitioner can stand behind the output.
You cannot sell what you cannot reproduce. And now the instrument reproduces.
The physics of business at scale and speed, accelerated by AI. That is what this work measures. One hundred seventeen runs in, the instrument is grounded.
Justin Greenbaum
Greenbaum Labs
March 2026