
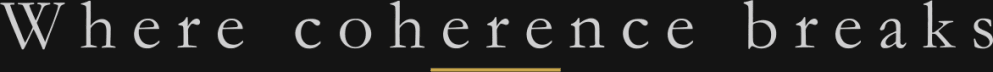

What’s Happened
Edition 1 introduced coherence as a structural property: truth, authority, and continuity reinforcing each other over time. This edition is about what happened when I tried to make it measurable.
Since the last update, I’ve been building a diagnostic pipeline. Software that takes what a company says about itself (center) and what the world says back (edge), then measures the gap. The system scores organizations on three vertices: Truth, Authority, and Continuity. The output is a structural diagnostic, not an opinion.
The target entity is Coinbase. Not because they’re broken. Because they’re public, data-rich, and operating at a scale where coherence failures become visible.
Thirteen runs later, the pipeline works.
The Pipeline
It runs on a local GPU. No cloud APIs for data processing. The models are open-weight (Qwen 32B). Every claim and observation traces back to a source document with a cryptographic hash. Provenance is not optional. It’s structural.
The pipeline has four steps:
Collect — Gather what the company says (press releases, job postings) and what the world sees (customer reviews, social media, news coverage).
Extract — Pull structured claims and observations from raw documents.
Score — Evaluate Truth (does center match edge?) and Authority (does the entity’s voice carry weight?). An adversarial Skeptic challenges every finding. Only sustained findings enter the evidence ledger.
Synthesize — Produce a diagnostic summary with failure modes, field notes, and a watch list.
Thirteen Runs
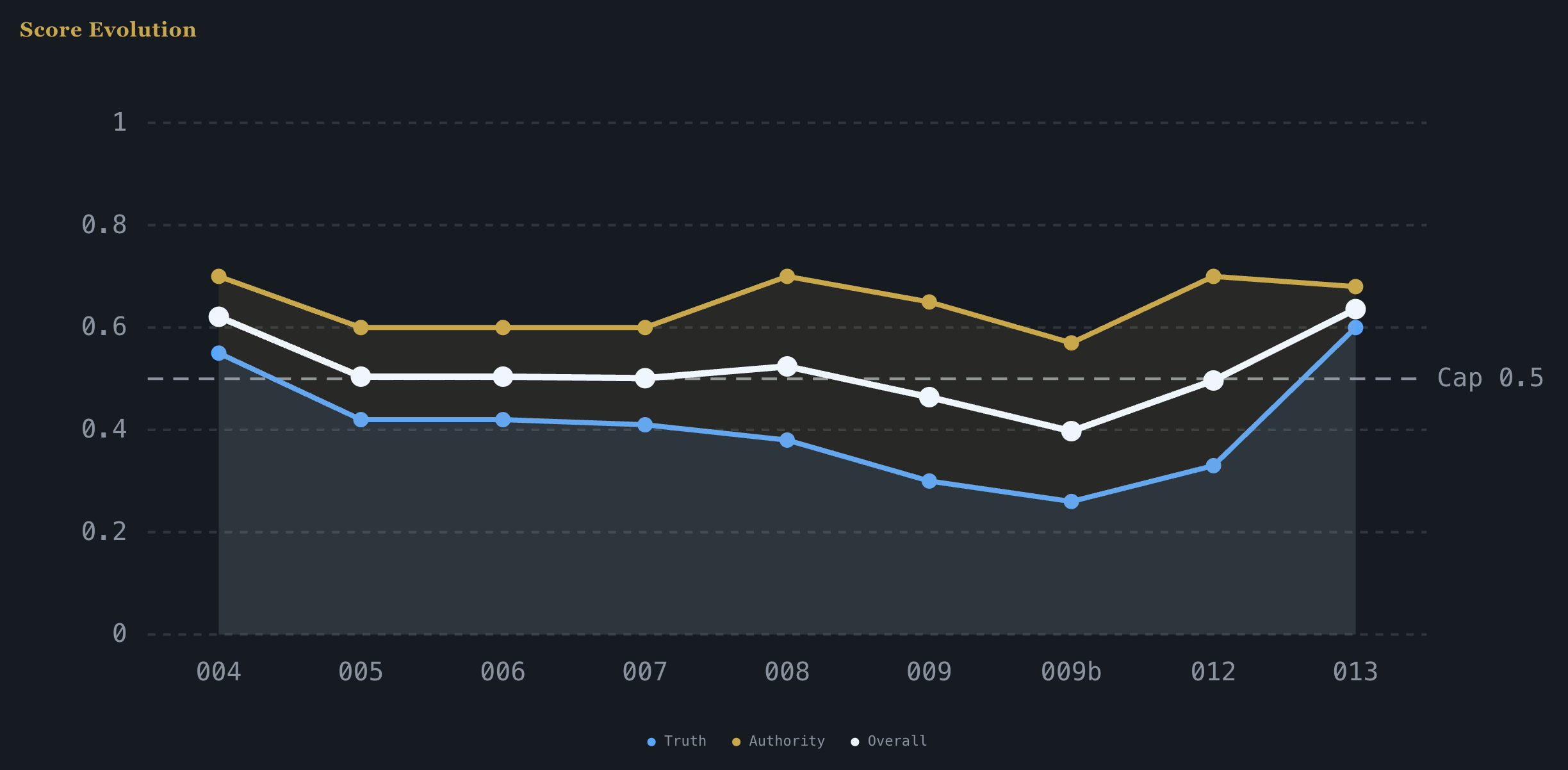
The run history tells the real story. Not the polished version. The actual one.
Runs 001-004 were scaffolding. Rule-based extraction, heuristic scoring. Establishing that the data moved through the system correctly. Run 004 produced the first real output: 296 claims, overall coherence 0.621. But 68% of the signal was unclassified. The pipeline was mechanically sound but structurally shallow.
Runs 005-007 introduced agent-powered extraction. The model reads the documents and produces structured claims and observations directly. Unclassified rate dropped from 68% to under 5%. Claims jumped to 1,335. Observations to 2,680. The system was seeing things the heuristics missed entirely.
Run 006 was the first fully unattended execution. Twelve hours, no manual intervention, every validation check passed. Run 007 confirmed repeatability.
Runs 008-011 were premature optimization. I tried to make it faster. Smaller model, larger batches. It worked mechanically (6x speedup) but broke structurally. Schema validation failed on 100% of first attempts. Four runs, three configurations, two killed early. The compounding lesson:
I was changing the engine while flying.
The root cause turned out to be a prompt conflict: two contradictory schemas in the same instruction set. Run 011 proved it wasn’t the model. The model was doing exactly what the prompt told it to do.
Run 012 was the reset. Back to the proven configuration, with three specific fixes. Zero schema failures across 276 batches. All validation checks passed. The largest single-run improvement in Authority (+0.13) came from adding center sources. Press releases and job postings made the organizational voice audible for the first time. Truth dropped because 1,319 center claims met only 23 edge observations. The pipeline correctly identified the imbalance.
Run 013 was the payoff. was the payoff. Full edge expansion. Social media and news coverage split into individual documents. The numbers:
1,377 claims. 4,736 observations.
Truth: 0.60. Up from 0.33. Edge depth restored.
Authority: 0.70. Capped — more on this below.
Overall coherence: 0.636.
13.7 hours. 73% of findings sustained by the Skeptic (11 of 15, 4 rejected). FM-01 detected again.
FM-01: Responsibility Compression at the Edge
This failure mode has appeared in every agent-powered run. Confidence 0.4 to 0.6. Across every model configuration, every data mix, every prompt version.
The pattern: responsibility concentrates where authority does not. Coinbase’s center narrative claims ownership of security, efficiency, and user experience. The edge data shows those responsibilities dispersing. Accountability for operational performance lands downstream without corresponding decision-making power. The diagnostic doesn’t measure whether Coinbase is good or bad at customer support. It measures whether the structure that owns those outcomes has the authority to change them.
This is not a model artifact. When a signal persists across nine runs with different extraction methods, different model sizes, and different data compositions, you’re looking at structure, not noise.
What’s Capped
Two binding constraints remain:
Authority is capped at 0.70 because the pipeline has no employee reviews. Customers and journalists see the outside. Employees see the inside. Without that source, the Authority scorer can’t fully assess whether power and accountability are aligned within the organization. Employee reviews are the single highest-leverage data gap.
Overall confidence is capped at 0.50 because all data comes from a single collection period. Continuity, the third vertex, requires temporal depth. One snapshot tells you the current state. Three tell you whether it’s getting better or worse.
These caps are not limitations of the model. They’re structural constraints designed into the system. The pipeline knows what it doesn’t know.
Why This Matters Economically
The business case for coherence is not moral. It is mechanical. When truth, authority, and continuity fall out of alignment, the organization generates friction: in revenue (customers experience something different from what’s promised), in talent (employees absorb structural failures disguised as performance problems), and in capital (investors price in narratives that the edge doesn’t support). That friction has a cost, and the cost compounds. Coherence measurement makes the friction visible before it becomes a write-down or a reorg or an exodus.
What I Learned
Schema failures are prompt-driven, not model-driven. When extraction breaks, check the instructions before blaming the model. The model does what you tell it to do, including when you tell it two contradictory things.
Don’t optimize what isn’t stable. Runs 008-011 should have been one run. The detour cost four attempts and a week. The principle is simple: get it right, prove it works, then make it fast.
Edge splitting was the highest-leverage change in pipeline history. Splitting consolidated staging files into individual documents produced a 206x increase in observations. Not a model change. Not a prompt change. A data format change.
Center sources make Authority audible. Adding press releases and job postings didn’t just add data. It gave the scoring agent visibility into what the organization is actually claiming. You can’t score authority if you can’t hear the voice making claims.
The record exists for the truth. Every run has a review. Every review documents what happened, what broke, and what was learned. The run reviews are not retrospective polish. They’re written the same day, before the lessons have time to soften.
What’s Next
Run 014 is staged. Employee reviews are being added to the collection. A normalizer tool now converts manually-sourced Glassdoor data into pipeline-compatible format. When that source comes online, Authority uncaps from 0.70.
The scoring agents are being tuned. Few-shot examples now show the Authority agent what structural differentiation looks like. Not just what score to produce, but how to reason about power, accountability, and organizational voice as distinct signals.
After 014, the focus shifts to repeatability. A second entity. A second collection period. The system needs to prove it measures coherence, not just Coinbase.
Decision & Responsibility Infrastructure was filed with the USPTO on February 10, 2026. Serial number 99645812. It names the field, not a product.
AR-001 Still Holds
Edition 1 established the first Accountability Record: *Automation may observe, summarize, and suggest, but may not decide.*
The pipeline embodies this. Every diagnostic output is a suggestion. Every finding requires human review. The Skeptic debate mechanism is adversarial, but the final judgment is not automated.
Thirteen runs in, the governance hasn’t changed. The capability has grown around it without eroding it.
That’s coherence in practice.
Justin Greenbaum
Greenbaum Labs
February 2026